nano-vllm 源码阅读
前言
最近突发奇想想要读一下 vllm 的源码,原因是对这个挺感兴趣的,另外之前接触过一段时间,但是一直没有深入下来了解过它的源码是怎么写的(顺便消磨点时间学点有用的),但是担心源码太多读不下来,所以就选择了更精简的版本 nano-vllm。下面是我边读边做的一些笔记,个人感觉还是非常详细的。另外内容难免有错误,还望能够在评论区指出,咱们一同学习进步。
项目结构
nano-vllm
├── bench.py
├── example.py
├── LICENSE
├── nanovllm
│ ├── config.py
│ ├── engine
│ │ ├── block_manager.py
│ │ ├── llm_engine.py
│ │ ├── model_runner.py
│ │ ├── scheduler.py
│ │ └── sequence.py
│ ├── __init__.py
│ ├── layers
│ │ ├── activation.py
│ │ ├── attention.py
│ │ ├── embed_head.py
│ │ ├── layernorm.py
│ │ ├── linear.py
│ │ ├── rotary_embedding.py
│ │ └── sampler.py
│ ├── llm.py
│ ├── models
│ │ └── qwen3.py
│ ├── sampling_params.py
│ └── utils
│ ├── context.py
│ └── loader.py
├── pyproject.toml
└── README.md其中
engine文件夹:nano-vllm 的核心,实现了 kv cache、paged attention 等功能layers文件夹:定义了模型的所有组件,例如 Attention、embed_head、layernorm 等models文件夹:利用layers中的组件定义了 qwen3 模型类utils文件夹:一些小工具
example.py
nano vllm 有一个非常棒的入口文件 example.py,我决定从这里开始自顶向下阅读
这个文件一共就只有 34 行,完成了 5 个动作
- 确定模型路径:
path = os.path.expanduser("~/huggingface/Qwen3-0.6B/") - 加载 model 和 tokenizer:
tokenizer = AutoTokenizer.from_pretrained(path)
llm = LLM(path, enforce_eager=True, tensor_parallel_size=1) # LLM 就是 LLMEngine 的一层名字上的包装- 确定采样参数:
sampling_params = SamplingParams(temperature=0.6, max_tokens=256) - 准备 prompts:
prompts = [
"introduce yourself",
"list all prime numbers within 100",
]
prompts = [
tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
for prompt in prompts
]- 推理:
outputs = llm.generate(prompts, sampling_params)
采样参数 SamplingParams
采样参数包括三个值
# nanovllm/sampling_params.py
from dataclasses import dataclass
@dataclass
class SamplingParams:
temperature: float = 1.0
max_tokens: int = 64
ignore_eos: bool = Falsetemperature: 在 attention 操作的 softmax 中使用的温度,控制生成下一个 token 的混乱程度,值越低(越接近 0)则结果越确定,值越高(1 或更高)则回答更多样。控制公式:
max_tokens: 控制最长回答长度,参见下面的代码:
# nanovllm/engine/scheduler.py, line 68:
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens:
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
self.running.remove(seq)
# nanovllm/engine/sequence.py, line 42:
@property
def num_completion_tokens(self):
return self.num_tokens - self.num_prompt_tokensignore_eos: 是否忽略eos(end of sequence),如果不忽略(值为False)的话,当一个 token 的 id 是代表eos时,会停止当前请求的生成。涉及到的代码如下:
# nanovllm/engine/scheduler.py, line 68
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens:
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
self.running.remove(seq)prompts
对于不同的模型,对话格式可能会有差别(不仅仅局限于 <|user|> 或 <|assistant|> 或 <|end_of_message|> 这类标签),可以使用 huggingface 提供的 apply_chat_template 方法便捷地进行 prompt 的准备,而无须手动调整格式,例如 huggingface 官方给出的例子:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
print(tokenizer.apply_chat_template(chat, tokenize=False))输出为
<|user|>
Hello, how are you?</s>
<|assistant|>
I'm doing great. How can I help you today?</s>
<|user|>
I'd like to show off how chat templating works!</s>需要注意的是,传入的 input 需要是 {"role": "xxx" "content": "yyy"} 这种格式的字典组成的列表,其中 “xxx” 的取值为:“user”, “assistant”, “system”,分别表示用户输入、模型回答、系统提示词。
当参数 tokenize 为 True 时,将返回 tokenize 之后的结果,还是用上面的例子,得到输出:
[523, 28766, 1838, 28766, 28767, 13, 16230, 28725, 910, 460, 368, 28804, 2, 28705, 13, 28789, 28766, 489, 11143, 28766, 28767, 13, 28737, 28742, 28719, 2548, 1598, 28723, 1602, 541, 315, 1316, 368, 3154, 28804, 2, 28705, 13, 28789, 28766, 1838, 28766, 28767, 13, 28737, 28742, 28715, 737, 298, 1347, 805, 910, 10706, 5752, 1077, 3791, 28808, 2, 28705, 13]而参数 add_generation_prompt 控制是否在输入最后加上提示 assistant 开始的 token,还是用上面的例子:
print(tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=False))
# 输出:
# <|user|>
# Hello, how are you?</s>
# <|assistant|>
# I'm doing great. How can I help you today?</s>
# <|user|>
# I'd like to show off how chat templating works!</s>
print(tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True))
# 输出:
# <|user|>
# Hello, how are you?</s>
# <|assistant|>
# I'm doing great. How can I help you today?</s>
# <|user|>
# I'd like to show off how chat templating works!</s>
# <|assistant|>这里就是多出了最后一行 <|assistant|>,提示模型应该开始补全 assistant 的部分了。
LLM (LLMEngine)
在 nano-vllm 中,LLM 就是 LLMEngine 包装了一下名字,便于阅读(但在 vllm 中并非这样,需要注意):
# nanovllm/llm.py
from nanovllm.engine.llm_engine import LLMEngine
class LLM(LLMEngine):
pass所以看看 LLMEngine:
- 共有六个方法,
__init__,exit,add_request,step,is_finished,generate,其中重要的有__init__、generate - 类成员五个
ps,events,model_runner,tokenizer,scheduler,其中核心成员为model_runner和scheduler
__init__
先看 __init__ 方法。接受一系列参数,范围在 Config 类的 field 内,所以我们先看看 Config 类:
import os
from dataclasses import dataclass
from transformers import AutoConfig
@dataclass
class Config:
model: str
max_num_batched_tokens: int = 16384
max_num_seqs: int = 512
max_model_len: int = 4096
gpu_memory_utilization: float = 0.9
tensor_parallel_size: int = 1
enforce_eager: bool = False
hf_config: AutoConfig | None = None
eos: int = -1
kvcache_block_size: int = 256
num_kvcache_blocks: int = -1
def __post_init__(self):
assert os.path.isdir(self.model)
assert self.kvcache_block_size % 256 == 0
assert 1 <= self.tensor_parallel_size <= 8
self.hf_config = AutoConfig.from_pretrained(self.model)
self.max_model_len = min(self.max_model_len, self.hf_config.max_position_embeddings)
assert self.max_num_batched_tokens >= self.max_model_len这里面一些关键的配置:
max_num_batched_tokens: 同时处理的最大 token 数量max_num_seqs: 同时处理的最大请求数量max_model_len: 最大对话长度gpu_memory_utilization: GPU 利用率tensor_parallel_size: 张量并行的规模enforce_eager: 是否使用 eager mode,与之相对的是 graph modekvcache_block_size: 存储 kv cache 时的块大小num_kvcache_blocks: kv cache 块数量
注意 __post_init__ 这个方法,它会在 dataclass 修饰器之后运行,可以用来参数校验以及动态调整成员值等
然后看初始化逻辑:首先为张量并行启动若干个进程
self.ps = [] # 所有子进程对象,方便管理(终止、join 等)
self.events = [] # 所有事件对象,用于进程间同步
ctx = mp.get_context("spawn") # 得到多进程上下文,使用 spawn 模式来避免 fork 时的 CUDA 问题
for i in range(1, config.tensor_parallel_size): # 注意是从 1 开始,因为当前进程(父进程)0 占用了一个张量并行的位置
event = ctx.Event()
process = ctx.Process(target=ModelRunner, args=(config, i, event)) # 创建子进程,将会运行 ModelRunner(config, i, event)
process.start()
self.ps.append(process)
self.events.append(event) # 收集子进程和事件对象然后初始化 model_runner、tokenizer、scheduler:
self.model_runner = ModelRunner(config, 0, self.events) # 注意这里需要初始化当前进程的 model_runner,最后一个参数传入的是 self.events 列表而非单个事件,这是因为 rank 0 负责协调,能访问所有事件
self.tokenizer = AutoTokenizer.from_pretrained(config.model, use_fast=True)
config.eos = self.tokenizer.eos_token_id
self.scheduler = Scheduler(config)最后使用 atexit 包将 self.exit 方法注册为一个清理函数,保证程序退出时资源正常释放:
atexit.register(self.exit)exit
上面提到注册了一个清理函数 self.exit,下面来简单看看这个函数做了什么:
def exit(self):
self.model_runner.call("exit")
del self.model_runner
for p in self.ps:
p.join()只做了两件事情,一是让 model_runner 退出并释放 model_runner,二是将所有子进程对象进行 join 方法保证结束。
add_request
然后再来看看如何向 LLMEngine 中添加请求,这个功能由 add_request 方法实现:
def add_request(self, prompt: str | list[int], sampling_params: SamplingParams):
if isinstance(prompt, str):
prompt = self.tokenizer.encode(prompt)
seq = Sequence(prompt, sampling_params)
self.scheduler.add(seq)整体逻辑很好理解,我们来看一下 Sequence 这个类,定义在 nanovllm/engine/sequence.py 中。一个该类的对象包含了一个请求的完整信息。这个类先用到了一个辅助类 SequenceStatus,是一个枚举类,有 WAITING,RUNNING,FINISHED 三个状态。
这个类有两个全类共享变量 block_size 和 counter,前者暂时不考虑(至少目前为止我们还用不到它,之后再分析),后者用于计算序列 id。__init__ 方法如下:
def __init__(self, token_ids: list[int], sampling_params = SamplingParams()):
self.seq_id = next(Sequence.counter)
self.status = SequenceStatus.WAITING
self.token_ids = copy(token_ids)
self.last_token = token_ids[-1]
self.num_tokens = len(self.token_ids)
self.num_prompt_tokens = len(token_ids)
self.num_cached_tokens = 0
self.block_table = []
self.temperature = sampling_params.temperature
self.max_tokens = sampling_params.max_tokens
self.ignore_eos = sampling_params.ignore_eos从成员的名称即可看出该成员的用处,还是很容易理解的。接着看看几个需要注意的类方法或 property。对于 num_completion_tokens 方法,使用到的成员变量 num_tokens 和 num_prompt_tokens 在这个序列还没有被处理的时候是相等的,此时的 num_completion_tokens 就是 0;当模型生成完毕后,num_tokens 增加,此时得到的 num_completion_tokens 就是最终生成回复的 token 数量。
__getstate__ & __setstate__
然后我们来看 __getstate__ 和 __setstate__ 这两个方法(参考 https://stackoverflow.com/questions/1939058/simple-example-of-use-of-setstate-and-getstate),它们用于 pickle 模块进行 loads 和 dumps
def __getstate__(self):
return (self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table,
self.token_ids if self.num_completion_tokens == 0 else self.last_token)
def __setstate__(self, state):
self.num_tokens, self.num_prompt_tokens, self.num_cached_tokens, self.block_table = state[:-1]
if self.num_completion_tokens == 0:
self.token_ids = state[-1]
else:
self.last_token = state[-1]它们在 nanovllm/engine/model_runner.py 中的 ModelRunner 类的 read_shm 和 write_shm 方法中(作为 *args 的一个组成部分)使用
# read_shm
method_name, *args = pickle.loads(self.shm.buf[4:n+4])
# write_shm
data = pickle.dumps([method_name, *args])
n = len(data)
self.shm.buf[0:4] = n.to_bytes(4, "little")
self.shm.buf[4:n+4] = data最后我们回到 block_size 这个成员变量,它是 paged attention 的一个参数,表示一个块的大小(不了解 paged attention 的话可以看下这篇知乎专栏相关的部分),那么剩下的 num_cached_blocks、num_blocks、last_block_num_tokens 等成员函数的功能就显而易见了。
generate
从 add_request 中可以看出来,每一个 prompt 都需要对应一个 SamplingParams 对象,联想当在实际推理时,我们只会指定一次 SamplingParams 成员的值,不难推测一定在某个地方会创建一个 list 的成员值相同的 SamplingParams 对象。这正在 LLMEngine 的 generate 方法中实现了:
由此我们可以知道,完全可以为一批请求分别给不同的 SamplingParams,来实现同时处理多用户不同性质(采样温度等)的请求
# nanovllm/engine/llm_engine.py, line 59
def generate(
self,
prompts: list[str] | list[list[int]],
sampling_params: SamplingParams | list[SamplingParams],
use_tqdm: bool = True,
) -> list[str]:
if use_tqdm:
pbar = tqdm(total=len(prompts), desc="Generating", dynamic_ncols=True)
if not isinstance(sampling_params, list):
sampling_params = [sampling_params] * len(prompts) # 这里处理不是列表的情况,默认所有序列生成参数相同
for prompt, sp in zip(prompts, sampling_params):
self.add_request(prompt, sp) # 调用上一部分提到的 add_request 方法
outputs = {}
prefill_throughput = decode_throughput = 0.
while not self.is_finished():
t = perf_counter()
output, num_tokens = self.step() # step 方法,执行一步推理,我们在下一部分来看
if use_tqdm:
if num_tokens > 0: # 约定大于 0 时是 prefill,小于 0 时是 decode
prefill_throughput = num_tokens / (perf_counter() - t)
else:
decode_throughput = -num_tokens / (perf_counter() - t)
pbar.set_postfix({
"Prefill": f"{int(prefill_throughput)}tok/s",
"Decode": f"{int(decode_throughput)}tok/s",
})
# 下面开始处理返回值,由于这些值和 step 方法相关,建议先看 step 的实现
for seq_id, token_ids in output:
outputs[seq_id] = token_ids
if use_tqdm:
pbar.update(1)
outputs = [outputs[seq_id] for seq_id in sorted(outputs)]
outputs = [{"text": self.tokenizer.decode(token_ids), "token_ids": token_ids} for token_ids in outputs]
if use_tqdm:
pbar.close()
return outputsstep
接下来看 step 方法:
# nanovllm/engine/llm_engine.py, line 48
def step(self):
seqs, is_prefill = self.scheduler.schedule() # scheduler 负责规划每一步需要向前推理的请求,同时返回一个是否处于 prefill 阶段的 bool 值
token_ids = self.model_runner.call("run", seqs, is_prefill) # 让实际模型跑一步得到新的 token ids
self.scheduler.postprocess(seqs, token_ids) # 后处理
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished] # 只返回已经完成的请求
num_tokens = sum(len(seq) for seq in seqs) if is_prefill else -len(seqs) # 这里如果是 decode 阶段则会返回一个负数,和上面的 generate 方法中对应的 if-else 判断语句逻辑相符
return outputs, num_tokens这里 is_prefill 是用于判断对应的请求是否处于 prefill 阶段。这个阶段是指请求是否是第一次被处理,此时推理一步需要将 prompt 中所有 token 都计算 kv cache 并生成第一个 token,和之后的每一步只需计算新的一个 token 的 kv 有很大不同,前者需要一次性进行大量计算(compute-bound),而后者则需要少量多次计算(memory-bound)。针对这两种截然不同的特性需要有不同的优化方法,这是后话,有机会再写。
另外 scheduler 的 postprocess 方法和 schedule 方法我们暂时不清楚,就暂且放过,等到后面读 scheduler 相关的部分再来回顾。
至此我们对
LLMEngine的了解就足够了,接下来看看它的重要组件:ModelRunner和Scheduler
ModelRunner
在读 ModelRunner 定义之前,我们先统计一下它在 LLMEngine 中出现的地方:
# nanovllm/engine/llm_engine.py
# __init__
for i in range(1, config.tensor_parallel_size):
event = ctx.Event()
process = ctx.Process(target=ModelRunner, args=(config, i, event))
process.start()
self.ps.append(process)
self.events.append(event)
self.model_runner = ModelRunner(config, 0, self.events)
# exit
self.model_runner.call("exit")
del self.model_runner
# step
token_ids = self.model_runner.call("run", seqs, is_prefill)可以大致发现一共使用了它的 init、call、exit 三个功能,其中 exit 和 run 都是通过 call 方法间接调用的。我们来看看它的所有类方法:
# nanovllm/engine/model_runner.py
class ModelRunner:
def __init__(self, config: Config, rank: int, event: Event | list[Event]):
...
def exit(self):
...
def loop(self):
...
def read_shm(self):
...
def write_shm(self, method_name, *args):
...
def call(self, method_name, *args):
...
def warmup_model(self):
...
def allocate_kv_cache(self):
...
def prepare_block_tables(self, seqs: list[Sequence]):
...
def prepare_prefill(self, seqs: list[Sequence]):
...
def prepare_decode(self, seqs: list[Sequence]):
...
def prepare_sample(self, seqs: list[Sequence]):
...
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
...
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
...
def capture_cudagraph(self):
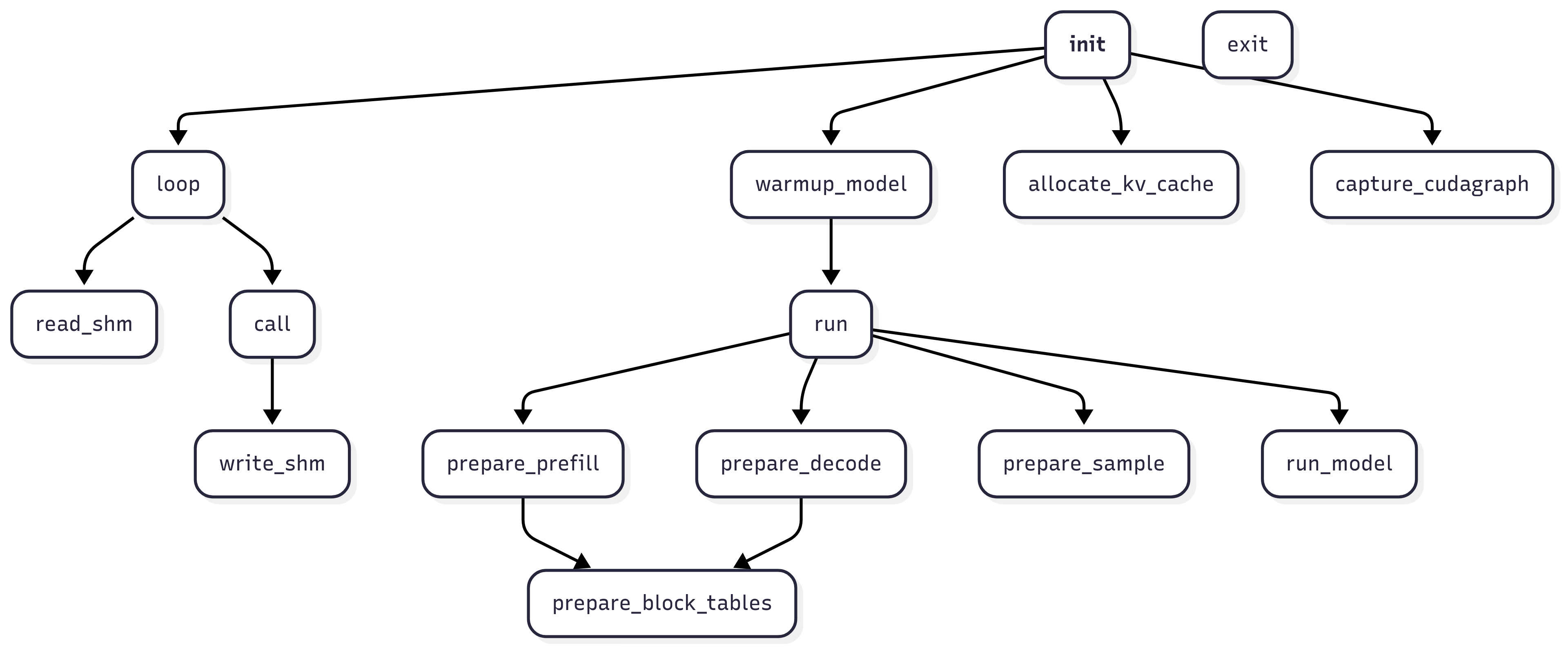
...相互之间的调用关系如下图所示:
__init__
首先还是先看 __init__:
def __init__(self, config: Config, rank: int, event: Event | list[Event]):
# 先设置 config 值
self.config = config
hf_config = config.hf_config
self.block_size = config.kvcache_block_size
self.enforce_eager = config.enforce_eager
self.world_size = config.tensor_parallel_size
self.rank = rank
self.event = event
# 启动进程组并绑定 CUDA 设备、设置 torch 数据类型
dist.init_process_group("nccl", "tcp://localhost:2333", world_size=self.world_size, rank=rank)
torch.cuda.set_device(rank)
default_dtype = torch.get_default_dtype()
torch.set_default_dtype(hf_config.torch_dtype)
torch.set_default_device("cuda")
# 加载模型和 sampler
self.model = Qwen3ForCausalLM(hf_config)
load_model(self.model, config.model)
self.sampler = Sampler()
# 预热,避免首次真实推理时出现不确定的延迟或内存不足的问题
self.warmup_model()
self.allocate_kv_cache()
# CUDA graph 相关,暂时不考虑
if not self.enforce_eager:
self.capture_cudagraph()
# 设置默认设备和 dtype
torch.set_default_device("cpu")
torch.set_default_dtype(default_dtype)
# 如果采用了张量并行,那么就使用共享内存来实现不同进程之间的通讯,在 read_shm 和 write_shm 中有使用,并且 rank=0 的进程负责创建,其他进程直接连接
if self.world_size > 1:
if rank == 0:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)
dist.barrier() # 先创建再等待其他进程同步
else:
dist.barrier() # 先同步得到 rank=0 进程创建的共享内存,然后再连接
self.shm = SharedMemory(name="nanovllm")
self.loop() # 其他进程进入 loop 开始循环,等待 rank=0 进程通过共享内存发送指令warmup_model
在继续查看“预热”部分的代码前,我们需要先了解大模型的推理过程中的显存占用情况。
在推理过程中,显存占用主要由这四个部分组成:模型参数、激活值、KV cache、计算的中间结果。相较于训练过程,1. 只需要保存当前激活值,因为不需要反向传播;2. 不需要保存优化器状态。其中模型参数是固定的,而激活值随训练进行呈周期性变化、KV Cache 由具体的样本长度和回复长度决定、中间结果几乎不能提前知道占用多少。
另一方面,在第一次调用 GPU 内核、内存分配或 cuBLAS/cuDNN 算子时,CUDA 运行时会做很多隐式初始化,包括分配显存、加载内核、建立工作流。
这会带来一个问题:如果我们直接开始推理,就有可能由于不知道如何分配显存而导致显存不足、第一次推理的延迟非常不确定(可能会很高),直到后续推理才逐渐正常的现象。当然这个情况也会受到 FlashAttention、PagedAttention 等因素影响,这里不做过多讨论。
所以在推理开始前,一般都会首先进行一次”预热”,也就是 warmup_model 方法:
def warmup_model(self):
# 清空显存并重置峰值显存的记录
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
# 使用最大负载来得到实际运行时的显存峰值占用
max_num_batched_tokens, max_model_len = self.config.max_num_batched_tokens, self.config.max_model_len
num_seqs = min(max_num_batched_tokens // max_model_len, self.config.max_num_seqs)
seqs = [Sequence([0] * max_model_len) for _ in range(num_seqs)] # 由于这次推理只需要起到预热的效果就行了,所以可以任意赋值
self.run(seqs, True) # 跑一遍refill 阶段
torch.cuda.empty_cache() # 清空显存然后根据得到的实际数值就可以来分配显存如何占用了,例如分配 KV Cache 的显存占用 allocate_kv_cache 方法。
从 __init__ 方法可以看到,warmup_model 在以下时机被调用:
- 模型加载完成后
- KV缓存分配之前
- CUDA图捕获之前
这个时机很关键,因为它确保了后续的内存分配(特别是KV缓存)能够基于准确的内存使用情况进行计算,所以 warmup_model 是一个重要的初始化步骤,它确保模型在正式服务之前已经完全准备就绪,并为后续的内存管理提供了准确的基准。
allocate_kv_cache
allocate_kv_cache 方法是在 推理前为模型分配 KV Cache。KV Cache(Key/Value 缓存)是保存注意力机制中历史 token 的中间结果的关键结构,具体为什么要缓存,缓存后如何使用可以参考 sglang 和 vllm 的论文。
def allocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
num_kv_heads = hf_config.num_key_value_heads // self.world_size
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * hf_config.head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0
self.kv_cache = torch.zeros(2, hf_config.num_hidden_layers, config.num_kvcache_blocks, self.block_size, num_kv_heads, hf_config.head_dim)
layer_id = 0
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1首先,代码通过 torch.cuda.mem_get_info() 和 torch.cuda.memory_stats() 获取 GPU 显存使用情况:
free,total给出当前剩余和总显存大小;used = total - free表示已经占用的显存;peak和current分别表示历史峰值分配量和当前分配量。
接下来,计算一个 单个 KV block 的大小:
block_bytes 表示 存储一个 KV cache block 需要的显存字节数,且这个 block 是 跨所有层 (num_hidden_layers) 的。可以理解为:如果我要为模型的所有层再存一批 token 的 KV cache,那么这批数据总共占多少字节
num_kv_heads = hf_config.num_key_value_heads // self.world_size
block_bytes = 2 * num_layers * block_size * num_kv_heads * head_dim * dtype_size- 2 对应 K 和 V 两个缓存;
num_layers是Transformer层数;block_size是每个 block 能存多少 token;num_kv_heads是分配到当前 rank 的 KV 头数(注意这里做了 // world_size 的切分);head_dim是每个注意力头的维度;- 最后乘上
dtype.itemsize得到字节数。
然后,代码根据显存利用率参数 config.gpu_memory_utilization,结合 total,used,peak,current 估算出还能分配多少空间,除以 block_bytes 就得到最多能放下多少个 KV block。
# config.num_kvcache_blocks = (可用显存字节) // block_bytes
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0 # 断言必须 > 0,保证至少能分配一块。接着,通过 torch.zeros 在 GPU 上一次性申请一整个 KV cache 张量,shape 为:
[2, num_layers, num_kvcache_blocks, block_size, num_kv_heads, head_dim]- 第一个维度 2:K 和 V 两个缓存;
num_layers:每层 Transformer 各自有一份 KV cache;num_kvcache_blocks:每层能存多少个 block;
其余维度对应注意力机制的 shape。
最后,遍历 self.model.modules(),把每一层的 k_cache 和 v_cache 指针指向这块大张量的切片,这样模型在推理时就能直接读写这块共享的 KV cache,而不需要单独为每层分配小块显存。
loop
然后来看看 loop 方法:
def loop(self):
while True:
method_name, args = self.read_shm()
self.call(method_name, *args)
if method_name == "exit":
break从 loop 方法中可以看出来,这个类的核心逻辑是通过共享内存(shared memory, shm)和事件(event)机制,实现不同进程之间的远程方法调用。具体来说,loop 会不断地从共享内存中读取一个 (method_name, args),然后调用对应的方法,如果方法名是 “exit”,就会跳出循环,结束进程。
def read_shm(self):
assert self.world_size > 1 and self.rank
self.event.wait()
n = int.from_bytes(self.shm.buf[0:4], "little")
method_name, *args = pickle.loads(self.shm.buf[4:n+4])
self.event.clear()
return method_name, args接着看 read_shm 方法:它首先通过 self.event.wait() 阻塞等待,直到有新的请求被写入共享内存。然后前 4 个字节存储了序列化数据的长度 n,接着用 pickle.loads 从共享内存中恢复出 (method_name, args)。可以看到,这里要求 world_size > 1 且当前进程不是 rank 0,也就是说,read_shm 专门为非主进程(worker)提供的接口,用于接收 rank 0 的控制消息。
def write_shm(self, method_name, *args):
assert self.world_size > 1 and not self.rank
data = pickle.dumps([method_name, *args])
n = len(data)
self.shm.buf[0:4] = n.to_bytes(4, "little")
self.shm.buf[4:n+4] = data
for event in self.event:
event.set()再看 write_shm 方法:与 read_shm 正好相对,这里要求 rank == 0,即只有主进程能写共享内存。它会先把 (method_name, args) 序列化成字节流写入共享内存,再通过 event.set() 唤醒所有等待的 worker 进程。这样,多个 worker 就能同时感知到新的调用。
def call(self, method_name, *args):
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args)
method = getattr(self, method_name, None)
return method(*args)call 方法其实是上层的统一接口 —— 如果当前进程是主进程(rank == 0),那么在调用本地方法之前,会先把请求广播到共享内存中,让所有 worker 一起执行;如果是 worker,则直接调用本地方法。
capture_cudagraph
然后来看看 capture_cudagraph 函数
@torch.inference_mode()
def capture_cudagraph(self):
config = self.config
hf_config = config.hf_config
max_bs = min(self.config.max_num_seqs, 512)
max_num_blocks = (config.max_model_len + self.block_size - 1) // self.block_size
input_ids = torch.zeros(max_bs, dtype=torch.int64)
positions = torch.zeros(max_bs, dtype=torch.int64)
slot_mapping = torch.zeros(max_bs, dtype=torch.int32)
context_lens = torch.zeros(max_bs, dtype=torch.int32)
block_tables = torch.zeros(max_bs, max_num_blocks, dtype=torch.int32)
outputs = torch.zeros(max_bs, hf_config.hidden_size)
self.graph_bs = [1, 2, 4, 8] + list(range(16, max_bs + 1, 16))
self.graphs = {}
self.graph_pool = None
for bs in reversed(self.graph_bs):
graph = torch.cuda.CUDAGraph()
set_context(False, slot_mapping=slot_mapping[:bs], context_lens=context_lens[:bs], block_tables=block_tables[:bs])
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # warmup
with torch.cuda.graph(graph, self.graph_pool):
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # capture
if self.graph_pool is None:
self.graph_pool = graph.pool()
self.graphs[bs] = graph
torch.cuda.synchronize()
reset_context()
self.graph_vars = dict(
input_ids=input_ids,
positions=positions,
slot_mapping=slot_mapping,
context_lens=context_lens,
block_tables=block_tables,
outputs=outputs,
)在大规模语言模型推理中,每次调用 CUDA kernel 都会有 CPU-GPU 通信开销,而 CUDA Graph 可以将一系列 kernel 调用”录制”下来,后续直接重放(replay),大幅降低调用延迟。
首先,代码准备了推理所需的各种张量,并且都按照最大可能的 batch size 来分配:
input_ids:当前要推理的 token IDpositions:每个 token 在序列中的位置slot_mapping:指向 KV cache 中具体存储位置的映射context_lens:每个序列的上下文长度block_tables:每个序列对应的 KV cache block 表outputs:模型输出的隐藏状态
接下来,代码定义了一系列要预捕获的 batch size:[1, 2, 4, 8, 16, 32, 48, …]。联想到实际推理时,不同时刻的 batch size 是动态变化的(有些序列完成了,有些刚开始),预先为常见的 batch size 录制 CUDA Graph,可以覆盖大部分推理场景。(比如对于 size 为 33 的情况,会选择 48 的图进行计算。
下面是核心的 CUDA Graph 捕获流程:
for bs in reversed(self.graph_bs): # 从大到小遍历 batch size,这样最大的内存需求会首先被满足
graph = torch.cuda.CUDAGraph()
set_context(...) # 设置上下文信息
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # warmup,避免编译、初始化等一次性操作被记录,提高录制的 cuda graph 效率
with torch.cuda.graph(graph, self.graph_pool): # 这个代码块中执行的所有CUDA操作都不会立即在GPU上运行,而是会被记录到 graph 对象中
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # capture
if self.graph_pool is None:
self.graph_pool = graph.pool() # 在成功捕获第一个 graph 后(即 bs 最大的 graph),保存其内存池,在后续继续捕获更小的 bs 的 graph 时共享,节约显存
self.graphs[bs] = graph
torch.cuda.synchronize() # 等待当前 graph 完全捕获
reset_context()最后,代码将所有输入张量保存到 self.graph_vars 中,这些张量会在后续 replay 时被复用——只需要修改张量内容,而不需要重新分配显存或重新构建计算图。
想要了解更多关于 cuda graph 及这段代码的含义,可以参考:bilibili、zhihu。
run
下面可以进入到 ModelRunner 类最后的一部分了,即 run 方法及其调用的一部分方法。
def run(self, seqs: list[Sequence], is_prefill: bool) -> list[int]:
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None
logits = self.run_model(input_ids, positions, is_prefill)
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()
return token_idsrun 函数是模型推理的主要入口点,它协调整个推理流程,包括输入准备、模型前向传播、采样和结果返回。
seqs: list[Sequence]:要处理的序列列表is_prefill: bool:标识当前是预填充阶段还是解码阶段
run 函数主要分为五个阶段(即一行代码一个阶段),此处先总述纲要,下面将进入函数一探究竟:
- 首先是输入准备阶段,进行
prepare_prefill或者prepare_decode. - 采样参数准备。只在主进程(rank 0)中准备采样参数,提取每个序列的温度参数用于控制生成的随机性,其他进程不需要采样参数,因为它们只参与模型计算。
- 模型前向传播。调用
run_model执行实际的模型推理:根据is_prefill和其他条件选择执行模式(eager 模式或CUDA 图模式),返回每个序列下一个 token 的 logits 分布。 - Token 采样,同样只在主进程中进行采样,使用 logits 和温度参数生成下一个 token,将结果转换为 Python 列表格式。
- 上下文清理,清理当前推理步骤的上下文信息。
首先来看 prepare_prefill 和 prepare_decode 两个方法:
def prepare_prefill(self, seqs: list[Sequence]):
input_ids = []
positions = []
cu_seqlens_q = [0]
cu_seqlens_k = [0]
max_seqlen_q = 0
max_seqlen_k = 0
slot_mapping = []
block_tables = None
for seq in seqs:
seqlen = len(seq)
input_ids.extend(seq[seq.num_cached_tokens:])
positions.extend(list(range(seq.num_cached_tokens, seqlen)))
seqlen_q = seqlen - seq.num_cached_tokens
seqlen_k = seqlen
cu_seqlens_q.append(cu_seqlens_q[-1] + seqlen_q)
cu_seqlens_k.append(cu_seqlens_k[-1] + seqlen_k)
max_seqlen_q = max(seqlen_q, max_seqlen_q)
max_seqlen_k = max(seqlen_k, max_seqlen_k)
if not seq.block_table: # warmup
continue
for i in range(seq.num_cached_blocks, seq.num_blocks):
start = seq.block_table[i] * self.block_size
if i != seq.num_blocks - 1:
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end)))
if cu_seqlens_k[-1] > cu_seqlens_q[-1]: # prefix cache
block_tables = self.prepare_block_tables(seqs)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)
return input_ids, positions
def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = []
context_lens = []
for seq in seqs:
input_ids.append(seq.last_token)
positions.append(len(seq) - 1)
context_lens.append(len(seq))
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
context_lens = torch.tensor(context_lens, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
block_tables = self.prepare_block_tables(seqs)
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables)
return input_ids, positions在 prepare_prefill 的最开始准备了几个参数,实际上这些参数在 Context 类(nanovllm/utils/context.py)中也有出现,负责管理上下文:
@dataclass
class Context:
is_prefill: bool = False
cu_seqlens_q: torch.Tensor | None = None
cu_seqlens_k: torch.Tensor | None = None
max_seqlen_q: int = 0
max_seqlen_k: int = 0
slot_mapping: torch.Tensor | None = None
context_lens: torch.Tensor | None = None
block_tables: torch.Tensor | None = None这个类很简单,这里列举一些类成员的作用:
cu_seqlens_k和cu_seqlens_q:全称是 “Cumulative Sequence Lengths for Query/Key”,用于在 FlashAttention 等注意力计算方法中,标识每个序列在整个批次中的起始和结束位置,从 0 开始方便后续累加max_seqlen_q:当前批次中,需要计算的 Query 序列的最大长度max_seqlen_k:当前批次中,所有 Key/Value 序列(包括已缓存部分)的最大长度slot_mapping:在 PagedAttention 中用于将逻辑上的 token 位置映射到物理上的 KV 缓存块(KV Cache blocks)中的具体位置(slot)block_tables:存放每个序列的块表(Block Table)。块表记录了该序列的 KV 缓存被存储在哪些物理块中。
回到 prepare_prefill 中,主要的处理逻辑在 for 循环中:
for seq in seqs:
seqlen = len(seq)
input_ids.extend(seq[seq.num_cached_tokens:])
positions.extend(list(range(seq.num_cached_tokens, seqlen)))
seqlen_q = seqlen - seq.num_cached_tokens # 这里减掉已经缓存的 token 是因为只需要当前的 query 来计算 value,往前的 query 已经不需要了
seqlen_k = seqlen
cu_seqlens_q.append(cu_seqlens_q[-1] + seqlen_q) # 记录当前 seq 的终止位置,起始位置就是上一个 seq 的终止位置
cu_seqlens_k.append(cu_seqlens_k[-1] + seqlen_k)
max_seqlen_q = max(seqlen_q, max_seqlen_q) # 记录 query 最大长度
max_seqlen_k = max(seqlen_k, max_seqlen_k)
# block_table 为空则跳过,这是因为在 warmup_model 中还没有分配实际的缓存块表
if not seq.block_table: # warmup
continue
for i in range(seq.num_cached_blocks, seq.num_blocks): # 遍历未 cache 的物理块
start = seq.block_table[i] * self.block_size
if i != seq.num_blocks - 1: # 如果不是最后一个块
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end))) # 添加计算出的物理 slot 索引范围在这之后,将所有结果用于设置上下文 set_context:
if cu_seqlens_k[-1] > cu_seqlens_q[-1]: # prefix cache
block_tables = self.prepare_block_tables(seqs)
# pin_memory=True 表示使用锁页内存,可以加速从 CPU 到 GPU 的数据传输
# non_blocking=True 表示可以不用等待数据传输完成就可以继续执行后续代码
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_q = torch.tensor(cu_seqlens_q, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
cu_seqlens_k = torch.tensor(cu_seqlens_k, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
set_context(True, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, None, block_tables)关于锁页内存是什么,可以阅读 https://zhuanlan.zhihu.com/p/462191421。
if 语句用于处理 prefix cache:当 key 的长度大于 query 的长度时,说明至少有一个序列使用了缓存,这会导致,这时调用 prepare_block_tables:
def prepare_block_tables(self, seqs: list[Sequence]):
max_len = max(len(seq.block_table) for seq in seqs) # 最大 block 块数
block_tables = [seq.block_table + [-1] * (max_len - len(seq.block_table)) for seq in seqs] # 将较短的 block table 右补齐至最长的长度
block_tables = torch.tensor(block_tables, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True) # 得到对齐后的 block table
return block_tables注意只有在存在 prefix cache 的情况下, prepare_block_tables 才会被调用,这是因为此时才有序列的 kv cache 需要被读取,才需要对齐 block table;否则这个时候由于所有的序列都是第一次 step,并不存在 kv cache,更不可能存在 block table。
之后的几行就是在设置上下文,较为简单。set_context 函数如下:
def set_context(is_prefill, cu_seqlens_q=None, cu_seqlens_k=None, max_seqlen_q=0, max_seqlen_k=0, slot_mapping=None, context_lens=None, block_tables=None):
global _CONTEXT
_CONTEXT = Context(is_prefill, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, slot_mapping, context_lens, block_tables)利用全局变量 _CONTEXT 来设置当前的上下文。
继续来看 prepare_decode:
def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = []
context_lens = []
for seq in seqs:
input_ids.append(seq.last_token)
positions.append(len(seq) - 1)
context_lens.append(len(seq)) # 上下文总长度
slot_mapping.append(seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1)
input_ids = torch.tensor(input_ids, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
positions = torch.tensor(positions, dtype=torch.int64, pin_memory=True).cuda(non_blocking=True)
slot_mapping = torch.tensor(slot_mapping, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
context_lens = torch.tensor(context_lens, dtype=torch.int32, pin_memory=True).cuda(non_blocking=True)
block_tables = self.prepare_block_tables(seqs) # 此时必然已经分配了 kv blocks 了,所以一定会需要对齐
set_context(False, slot_mapping=slot_mapping, context_lens=context_lens, block_tables=block_tables) # 由于 decode 阶段固定只生成一个 token,因此 cu_seqlens_q, max_seqlen_q 等变量不再需要
return input_ids, positions回想 decode 阶段每步只生成一个 token,上面的代码就不难理解了。和 prepare_prefill 相比,一个需要注意的点是 slot_mapping 在 prepare_decode 中为每一个序列存储一个整数,指向物理 kv cache 中用于存储新生成的 token 的 kv 值的 slot 位置:
seq.block_table[-1]:最后一个物理块的索引seq.block_table[-1] * self.block_size:最后一个物理块的起始位置seq.block_table[-1] * self.block_size + seq.last_block_num_tokens - 1:新 token 对应的物理 slot 位置
在准备好输入后(input_ids 和 positions),在 rank0(主进程)上将每一个 sample 的温度记录下来,以供之后对生成的 logits 进行采样:
temperatures = self.prepare_sample(seqs) if self.rank == 0 else None然后调用 run_model 进行一步推理,得到 logits:
logits = self.run_model(input_ids, positions, is_prefill)最后根据得到的 logits 和 temperatures 进行采样得到生成的新 token,随后立即重置上下文:
token_ids = self.sampler(logits, temperatures).tolist() if self.rank == 0 else None
reset_context()至此 run 函数已经分析完毕,只剩下 run_model 函数了。
run_model
@torch.inference_mode()
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))
else:
bs = input_ids.size(0)
context = get_context()
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)]
graph_vars = self.graph_vars
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"].fill_(-1)
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"].zero_()
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
graph.replay()
return self.model.compute_logits(graph_vars["outputs"][:bs])整个函数由一组 if-else 语句组成,其中当:
is_prefill=True:当前是 prefill 阶段,所有 prompt 的长度未定,导致计算图的形状是动态变化的,但 CUDA graph 要求形状固定,所以不能用 CUDA graph 加速self.enforce_eager=True:强制要求使用 eager modeinput_ids.size(0) > 512:batch size 过大,此时并没有为这么大的 batch size 预捕获 CUDA graph,所以只能用 eager mode
这些情况下,不使用 CUDA graph 加速。否则会执行:
bs = input_ids.size(0)
context = get_context()
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)] # 找到刚好超过 batch size 的预捕获值,下面的过程都是在“重现”当时捕获的场景
graph_vars = self.graph_vars
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"].fill_(-1)
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"].zero_()
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
graph.replay() # 触发 GPU 执行之前被捕捉和编译好的完整计算图,相当于用一个 CPU 指令就启动了模型中所有层、所有 CUDA Kernel 的执行
return self.model.compute_logits(graph_vars["outputs"][:bs])这里的 eager mode 可以简单的理解为“即时执行”的模式,CPU 会即时的启动模型用到的各种 CUDA kernel,也因此性能较 graph mode 更低,下面是一个简单的对比表格:
| 特性 | Eager Mode (动态图) | Graph Mode (静态图 / CUDA Graphs) |
|---|---|---|
| 执行方式 | 逐行、即时执行 | 先编译、后一次性执行 |
| 灵活性 | 极高,可处理动态形状和控制流 | 很低,要求形状和流程固定 |
| 性能 | 较低,受 Python 开销影响大 | 极高,CPU 开销非常小 |
| 调试 | 容易,像普通 Python 程序 | 困难,是黑盒执行 |
run_model 中用途 | Prefill 阶段、调试、处理不支持的批次大小 | Decode 阶段 (固定 batch size, 每次一个 token) |
至此,我们已经完全了解了
ModelRunner类了,对在准备好输入后模型是如何 ‘run’ 起来的有了全面的认知,我们可以移步到LLMEngine的另一个重要类成员,Scheduler去了。
Scheduler
和 ModelRunner 中一样的,我们来看看 LLMEngine 中哪些地方使用了 Scheduler 这个类:
# __init__
self.scheduler = Scheduler(config)
# add_request
self.scheduler.add(seq)
# step
seqs, is_prefill = self.scheduler.schedule()
...
self.scheduler.postprocess(seqs, token_ids)
# is_finished
return self.scheduler.is_finished()__init__
先来看看 __init__ 方法(很简单,没什么好说的):
def __init__(self, config: Config): self.max_num_seqs = config.max_num_seqs
self.max_num_batched_tokens = config.max_num_batched_tokens
self.eos = config.eos
self.block_manager = BlockManager(config.num_kvcache_blocks, config.kvcache_block_size)
self.waiting: deque[Sequence] = deque() # 等待被执行的序列
self.running: deque[Sequence] = deque() # 正在推理的序列辅助函数
is_finished 和 add 方法都很直观:
def is_finished(self):
return not self.waiting and not self.running
def add(self, seq: Sequence):
self.waiting.append(seq)schedule
最重要的是 schedule 方法:
def schedule(self) -> tuple[list[Sequence], bool]:
# prefill
scheduled_seqs = []
num_seqs = 0
num_batched_tokens = 0
while self.waiting and num_seqs < self.max_num_seqs:
seq = self.waiting[0] # 得到 waiting 队列中第一个,但暂时没有移出 waiting 队列
if num_batched_tokens + len(seq) > self.max_num_batched_tokens or not self.block_manager.can_allocate(seq): # 如果超出最大限度,直接停止 schedule
break
num_seqs += 1
self.block_manager.allocate(seq) # 分配新的 kv cache 块
num_batched_tokens += len(seq) - seq.num_cached_tokens
seq.status = SequenceStatus.RUNNING
self.waiting.popleft() # 此时才将该请求移出 waiting 队列
self.running.append(seq)
scheduled_seqs.append(seq)
# 由于上面进入 scheduled_seqs 的请求只能是 waiting 序列中的前若干项,所以必定是 prefill 阶段,返回的第二个参数为 True
if scheduled_seqs:
return scheduled_seqs, True
# decode
while self.running and num_seqs < self.max_num_seqs:
seq = self.running.popleft() # 取出 running 队列的最左边一个请求
# 如果不能添加这个请求,则
while not self.block_manager.can_append(seq):
# 如果已经有在 decode 阶段的请求,则抢占 running 队列中的最右边一个
if self.running:
self.preempt(self.running.pop())
# 否则“抢占”自己,即将 seq 放回 waiting 队列的最左边
else:
self.preempt(seq)
break
# 如果能够直接将 seq 添加进 running 队列
else:
num_seqs += 1
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, False这里 prefill 总是优先于 decode 的。这样做的原因是希望能够尽快给用户反馈,不用等待太久(TTFT 更小),代价是长序列的生成时间会变长(TBT 变大),且更容易出现所谓系统抖动的现象,即花费了大量时间在任务调度和上下文切换上,而不是在实际的推理计算上,从而降低了系统的整体有效吞吐量。
这里的调度策略是一个非常简单的形式,完全可以根据实际场景进行进一步的优化。
schedule 方法还用到了 preempt 方法用于抢占资源,逻辑比较简单:
def preempt(self, seq: Sequence):
seq.status = SequenceStatus.WAITING
self.block_manager.deallocate(seq)
self.waiting.appendleft(seq)另外还有 postprocess 方法,用于 step 后后处理请求和新生成的 tokens。
def postprocess(self, seqs: list[Sequence], token_ids: list[int]) -> list[bool]:
for seq, token_id in zip(seqs, token_ids):
seq.append_token(token_id) # 添加新 token
if (not seq.ignore_eos and token_id == self.eos) or seq.num_completion_tokens == seq.max_tokens: # 生成了 eos 或达到最大 token 数量
seq.status = SequenceStatus.FINISHED
self.block_manager.deallocate(seq)
self.running.remove(seq)BlockManager
到目前为止,我们已经学习了 LLMEngine 和它的主要方法以及成员 ModelRunner 和 Scheduler,而在 Scheduler 中,还有一个非常重要的成员 BlockManager,接下来我们就继续补全这一块的代码
BlockManager 肯定是要管理 Block 的,所以先看看 Block 这个类:
class Block:
def __init__(self, block_id):
self.block_id = block_id
self.ref_count = 0
self.hash = -1
self.token_ids = []
def update(self, hash: int, token_ids: list[int]):
self.hash = hash
self.token_ids = token_ids
def reset(self):
self.ref_count = 1
self.hash = -1
self.token_ids = []block_id:标识每个 blockref_count:当前 block 被引用了多少次(例如 prefix cache)hash:根据token_ids计算出的 hash 值,默认 -1 表示当前块尚未生成完成token_ids:当前 block 包含的 token ID 列表
下面这张是 BlockManager 类的类方法之间的调用关系图,

接下来我们依次阅读这个类的函数。
__init__
def __init__(self, num_blocks: int, block_size: int):
self.block_size = block_size
self.blocks: list[Block] = [Block(i) for i in range(num_blocks)]
self.hash_to_block_id: dict[int, int] = dict()
self.free_block_ids: deque[int] = deque(range(num_blocks))
self.used_block_ids: set[int] = set()初始化函数,变量如其名。
辅助函数
def can_allocate(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= seq.num_blocks
def can_append(self, seq: Sequence) -> bool:
return len(self.free_block_ids) >= (len(seq) % self.block_size == 1)can_allocate:能否再分配一个 blockcan_append:是否能够再追加一个 token,len(seq) % self.block_size == 1表示仅当恰好超出一个 token 时,才新分配一个 block
allocate
然后我们来看看 allocate 这个函数,它主要用于为给定的 seq 分配 block
def allocate(self, seq: Sequence):
assert not seq.block_table # 没有被分配过
h = -1 # hash 值,默认 -1
cache_miss = False # 是否 cache 命中
for i in range(seq.num_blocks):
token_ids = seq.block(i) # 获取第 i 个 block 的 token_ids
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1 # 如果 token_ids 可以构成一个完整的 block,则根据 token_ids 来为这个 block 计算一个 hash 值用于辨认,否则如果是不完整的块,则默认 hash 值为 -1
block_id = self.hash_to_block_id.get(h, -1)
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss: # 缓存不命中则新分配一个 block
block_id = self.free_block_ids[0] # 注意这里只“引用”了第一个空闲块的 id,没有真正取出来
block = self._allocate_block(block_id) # 在这里正式分配
else: # 缓存命中
seq.num_cached_tokens += self.block_size
if block_id in self.used_block_ids: # 如果这个命中的块正在被其他请求使用
block = self.blocks[block_id]
block.ref_count += 1
else: # 否则这个块是空闲的,需要通过 _allcate_block 来重新申明分配这个块
block = self._allocate_block(block_id)
# 如果是一个完整块,则更新 hash 值和 token_ids
if h != -1:
block.update(h, token_ids)
self.hash_to_block_id[h] = block_id
# 更新 seq 的 block table
seq.block_table.append(block_id)其中使用了 _allocate_block 函数来分配当前未被引用的块:
def _allocate_block(self, block_id: int) -> Block:
block = self.blocks[block_id]
assert block.ref_count == 0 # 分配这个块的前提是这个块当前是未被引用的
block.reset()
self.free_block_ids.remove(block_id)
self.used_block_ids.add(block_id)
return self.blocks[block_id]以及 compute_hash 函数用来计算每个块的 hash 值:
@classmethod
def compute_hash(cls, token_ids: list[int], prefix: int = -1):
h = xxhash.xxh64()
if prefix != -1:
h.update(prefix.to_bytes(8, "little"))
h.update(np.array(token_ids).tobytes())
return h.intdigest()这里需要注意的是 prefix,即链式哈希的使用。这是为了避免在不同请求中出现了相同缓存块时,缓存被错误的复用。在上面的 allocate 函数中,这个 prefix 会随 for 循环而更新,从而实现自动的链式哈希。
deallocate
继续来看 deallocate 函数:
def deallocate(self, seq: Sequence):
for block_id in reversed(seq.block_table): # 倒序释放
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0:
self._deallocate_block(block_id)
seq.num_cached_tokens = 0
seq.block_table.clear()逻辑很简单,不多说。其中使用的 _deallocate_block 函数如下:
def _deallocate_block(self, block_id: int) -> Block:
assert self.blocks[block_id].ref_count == 0
self.used_block_ids.remove(block_id)
self.free_block_ids.append(block_id)may_append
最后来看 may_append 函数:
def may_append(self, seq: Sequence):
block_table = seq.block_table
last_block = self.blocks[block_table[-1]]
# 刚好多出一个 token,则新分配一个 block
if len(seq) % self.block_size == 1:
assert last_block.hash != -1
block_id = self.free_block_ids[0]
self._allocate_block(block_id)
block_table.append(block_id)
# 刚好满一个 block,则为该 block(seq 最后一个 block)更新 hash 值,并记录到 hash_to_block_id 表中
elif len(seq) % self.block_size == 0:
assert last_block.hash == -1
token_ids = seq.block(seq.num_blocks-1)
prefix = self.blocks[block_table[-2]].hash if len(block_table) > 1 else -1
h = self.compute_hash(token_ids, prefix)
last_block.update(h, token_ids)
self.hash_to_block_id[h] = last_block.block_id
# 否则块处于中间态,hash 值必定是 -1
else:
assert last_block.hash == -1这个函数用于 Scheduler 类的 schedule 函数的 decode 阶段,当 self.block_manager.can_append(seq)=True 时(即能够为 seq 新追加一个 token 时),检查是否需要为该 seq 的 block_table 新增加一个 block。
至此,
BlockManager类的学习就结束了,nano-vllm 的绝大部分内容也已学习完成。
Model & Sampler
最后我们回到 ModelRunner 中的 model 和 sampler 两个成员。简单看看 sampler:
class Sampler(nn.Module):
def __init__(self):
super().__init__()
@torch.compile
def forward(self, logits: torch.Tensor, temperatures: torch.Tensor):
logits = logits.float().div_(temperatures.unsqueeze(dim=1))
probs = torch.softmax(logits, dim=-1)
sample_tokens = probs.div_(torch.empty_like(probs).exponential_(1).clamp_min_(1e-10)).argmax(dim=-1)
return sample_tokens然后是 model 的使用位置:
# __init__
self.model = Qwen3ForCausalLM(hf_config)
load_model(self.model, config.model)
# allocate_kv_cache
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1
# run_model
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))
else:
...
return self.model.compute_logits(graph_vars["outputs"][:bs])
# capture_cudagraph
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # warmup
with torch.cuda.graph(graph, self.graph_pool):
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # capture具体的模型定义见 layers 和 models 层,我把这部分和下面的 KV Cache 合并讲解。
KV Cache
到目前为止,我们已经完整的阅读了一遍 nano-vllm 的 engine 部分的所有代码了,但是以上都是对各个“小部件”的分开阅读,没有一个全链路的理解。所以我觉得有必要从一个更“宏观”一点的视角来分析 nano-vllm 中的一些功能。那么就让我们从 KV Cache 开始吧。
我们将 KV cache 的全链路拆开,从“内存布局/分配 前缀缓存与分页表 预填充(prefill) 解码(decode) 复用/淘汰与调度”这几个环节,逐步来讲是怎么运作的。
Overview
- 统一的 KV Cache 池在 GPU 上一次性申请,按“块(block) × 槽(slot)”分页管理,所有层共享同一组 block 索引。
- 每个请求的上下文被切成固定大小的块(block_size,默认 256),其 KV 存在“全局块池”中,对应关系保存在每条序列的
block_table里。 - 前缀复用依靠“滚动哈希 + 引用计数”:相同前缀的块映射到同一块 ID,并用 ref_count 做共享与回收。
- 执行期通过
slot_mapping精确描述每一个 step 要写入哪些槽位,Triton kernel 把 K/V 写到对应 cache 槽;FlashAttention 读 cache 完成注意力。 - 调度器在“预填充/解码”两个阶段分别保证块资源可用,不够就抢占(preempt)并回收。
内存布局与分配
nanovllm/engine/model_runner.py::allocate_kv_cache
kv_cache 一次性在 GPU 上申请形状为 self.kv_cache.shape = [2, num_layers, num_kvcache_blocks, block_size, num_kv_heads, head_dim] 的一整块,然后通过 warmup_model 的结果估计出 KV Cache 的块数量,然后遍历模型模块,找到带 k_cache/v_cache 属性的注意力层,把每层的视图指到 self.kv_cache[0 or 1, layer_id] 上。这样所有层共享同一组 block 编号。
BlockManager
nanovllm/engine/block_manager.py,配合 nanovllm/engine/sequence.py
首先对每个序列切块,按照块大小 Sequence.block_size=256,token_ids 被切成若干块(最后一块可能不满)。这些块都由 BlockManager 负责管理分配和释放。用 prefix hash 来标识每一个块(hash_to_block_id),可以实现不同请求之间的复用(如 system prompt)。当且仅当一个块被 token 填满时,才会计算其 hash 值,否则默认为 -1。在 prefill 和 decode 阶段都会对新增加的 token 进行 block 分配或者抢占操作。
每一个 seq 的块分配结果记录在 seq.block_table中,映射是:逻辑块索引 全局块 ID。
Context
nanovllm/utils/context.py、
nanovllm/layers/attention.py::store_kvcache
Context 类在之前就已经提到过了,用于管理模型推理的上下文。在 prefill 和 decode 阶段分别提供不同的数据:
- prefill:
cu_seqlens_q/k、max_seqlen_q/k、slot_mapping、block_tables(如有前缀缓存)。 - decode:
slot_mapping、context_lens、block_tables。
再回忆一下,slot_mapping表示了当前 step 会写入哪些槽位:
- prefill:对未命中的块(新块)或最后一块的新增部分生成连续的全局槽位索引。
- decode:每条序列只写入当前 token 的槽位,即
block_table[-1] * block_size + last_block_num_tokens - 1。
可以统一为如下形式 slot = block_id * block_size + offset_in_block
在实际实现中,会通过 triton 实现的 store_kvcache_kernel 逐 token 把 key/value 写入 k_cache/v_cache 对应 slot_mapping 的位置。
# Attention.forward
k_cache, v_cache = self.k_cache, self.v_cache
if k_cache.numel() and v_cache.numel():
store_kvcache(k, v, k_cache, v_cache, context.slot_mapping) # 存储新的 k(ey), v(alue)
# store_kvcache
def store_kvcache(key: torch.Tensor, value: torch.Tensor, k_cache: torch.Tensor, v_cache: torch.Tensor, slot_mapping: torch.Tensor):
N, num_heads, head_dim = key.shape
D = num_heads * head_dim
assert key.stride(-1) == 1 and value.stride(-1) == 1
assert key.stride(1) == head_dim and value.stride(1) == head_dim
assert k_cache.stride(1) == D and v_cache.stride(1) == D
assert slot_mapping.numel() == N
store_kvcache_kernel[(N,)](key, key.stride(0), value, value.stride(0), k_cache, v_cache, slot_mapping, D)这里 store_kvcache_kernel 如下:
@triton.jit
def store_kvcache_kernel(
key_ptr,
key_stride,
value_ptr,
value_stride,
k_cache_ptr,
v_cache_ptr,
slot_mapping_ptr,
D: tl.constexpr,
):
idx = tl.program_id(0)
slot = tl.load(slot_mapping_ptr + idx)
if slot == -1: return
key_offsets = idx * key_stride + tl.arange(0, D)
value_offsets = idx * value_stride + tl.arange(0, D)
key = tl.load(key_ptr + key_offsets)
value = tl.load(value_ptr + value_offsets)
cache_offsets = slot * D + tl.arange(0, D)
tl.store(k_cache_ptr + cache_offsets, key)
tl.store(v_cache_ptr + cache_offsets, value)将新的 k, v 储存到现有的 k_cache, v_cache 之后。之后模型运行时直接调用 flash_attn 提供的接口 flash_attn_with_kvcache 和 flash_attn_varlen_func 即可。
有关 triton,可以参考:https://zhuanlan.zhihu.com/p/527937835;有关 flash attention,可以参考:https://zhuanlan.zhihu.com/p/668888063。
Prefill 阶段的数据流
nanovllm/engine/scheduler.py::schedule(prefill 分支),nanovllm/engine/model_runner.py::prepare_prefill
schedule函数在 waiting 队列里拉取序列,检查 token 总预算与块可用量(block_manager.can_allocate),满足则调用allocate(seq)完成块绑定和前缀复用判定。构造完毕后输入模型执行。prepare_prefill函数构造张量,准备好如下 metadata 后设置全局上下文set_context(True, cu_seqlens..., slot_mapping, block_tables):
input_ids:仅包含“未缓存的 token”的 ID(从seq.num_cached_tokens起)positions:对应 token 的绝对位置cu_seqlens_q/k、max_seqlen_q/k:变长前向所需slot_mapping:把需要新写入的 token 映射到全局槽位(遍历本序列从num_cached_blocks到num_blocks的块;最后一块只取已存在 token 数)block_tables:若sum_k > sum_q(即存在前缀块),则构建二维表,行是 batch 内不同序列的block_table,用 -1 pad 到同长
- 在
Attention模块:
- 如果已存在
block_tables(即存在前缀缓存):把k/v指向缓存(k_cache/v_cache),调用flash_attn_varlen_func(..., block_table=block_tables);同时 Triton 内核按slot_mapping把新 token 的k/v追加写入缓存。 - 如果没有前缀缓存(warmup 之类):会走纯 QKV 路径,但写 cache 的 slot_mapping 为空(N=0),不会写。
对于第三点,可以回顾一下 prepare_prefill 中的这段逻辑:
if not seq.block_table: # warmup
continue
for i in range(seq.num_cached_blocks, seq.num_blocks):
start = seq.block_table[i] * self.block_size
if i != seq.num_blocks - 1:
end = start + self.block_size
else:
end = start + seq.last_block_num_tokens
slot_mapping.extend(list(range(start, end)))可以知道当在 warmup 等没有前缀缓存的情况下,slot_mapping 不会被处理,因而为空。
简单来说就是:
- 新请求入队 Scheduler prefill:
BlockManager.allocate复用满块、分配未命中块;prepare_prefill生成 slot_mapping 与(如有)block_tables;- 注意力用
flash_attn_varlen读前缀块的 cache,同时写新 token 的 KV到 cache。
Decode 的数据流
nanovllm/engine/scheduler.py::schedule(decode 分支),model_runner.py::prepare_decode
- 在
schedule函数中,在 running 队列上依次取出,如果即将需要新块但没有空闲块,则preempt其他/自己来释放块,否则调用block_manager.may_append(seq)做两件事:- 如果当前长度
len(seq) % block_size == 1(即刚进入新块的第一个 token):提前从free_block_ids列表中分配一个新 block_id,并加入seq.block_table,确保即将写入的槽有实体块。 - 如果
len(seq) % block_size == 0(上个 step 正好写满了一整块):此时为这个刚刚补满的块计算滚动哈希,写入hash_to_block_id,使之成为可复用的前缀块。
- 如果当前长度
- 在
prepare_decode函数中,同prepare_prefill一样准备一些 metadata,然后设置上下文set_context(False, slot_mapping, context_lens, block_tables):
input_ids: 每条序列取last_token作为本步输入positions:len(seq) - 1slot_mapping: 指向当前输入 token 的槽位,即block_table[-1] * block_size + last_block_num_tokens - 1context_lens: 每条序列当前上下文长度;block_tables: 和 prefill 一致,用于 FlashAttention 索引缓存
- 在
Attention模块块中调用flash_attn_with_kvcache(q.unsqueeze(1), k_cache, v_cache, cache_seqlens=context_lens, block_table=block_tables, causal=True)来计算的同时,Triton 内核按slot_mapping将当前输入 token 的 K/V 加入到缓存。 - 取出 logits 采样下一个 token,
postprocess里seq.append_token(token_id)增长长度并在达到结束条件时回收块。
简单来说就是:
- 进入 decode 循环(每 step):
BlockManager.may_append在需要时分配新块/为满块计算哈希;prepare_decode设置当前输入 token 的 slot_mapping, context_lens, block_tables;- 写当步 KV,注意力用
flash_attn_with_kvcache读 cache; - 采样得到下一个 token,append 进序列;
- 触发结束则回收块。
- 资源不足时 preempt 其他序列或自身,释放其块,稍后条件允许再继续。
preempt 与调度策略
nanovllm/engine/scheduler.py 与 nanovllm/engine/block_manager.py
- 正常结束:
postprocess发现到 EOS 或达到max_tokens,标记FINISHED,block_manager.deallocate(seq)逆序减少各块ref_count,为 0 的块归还空闲队列。 - decode 阶段资源紧张/抢占:
schedule的 decode 分支尝试can_append,当需要新块而没有空闲块时,若还有其他运行中序列,先preempt(self.running.pop());否则preempt(seq)自己(把整条序列回到 waiting 并释放其所有块)。其中preempt会:- 把序列状态改为
WAITING block_manager.deallocate(seq)释放全部块(ref—,为 0 的块回 free list)- 把序列放回 waiting 队列头部,等待下一轮资源满足再来。
- 把序列状态改为
- 缓存一致性与碰撞:
- 复用基于“滚动哈希 + token_ids 全等检查”,发生哈希碰撞会被 token_ids 不相等拦下,走 miss 分配新块。
- “未满块”没有哈希,不参与复用,直至填满后在下一次
may_append时确立哈希。
多卡/Tensor Parallel
nanovllm/engine/model_runner.py
num_kv_heads在多卡下按// tensor_parallel_size切分,每个 rank 只承载自己的 KV 头分片,相应的k_cache/v_cache也是本 rank 局部的。- world_size > 1 时 rank0 负责采样,进程间通过共享内存传递方法调用与采样结果;KV cache 管理逻辑在各 rank 本地执行。
至此 KV cache 的分析也已结束,相信你也已经基本掌握了 nano-vllm 的绝大部分内容,如果还有其他想要补充的欢迎评论区留言~
