

NOTE以下内容几乎为 猛猿 的系列文章的阅读笔记,推荐阅读原文以获得最佳体验。
Overview
训练模型的目标:更大、更快,即 GPU 提升 倍,模型大小或训练速度也能提升 倍
- GPU 内存限制:模型参数、中间结果(backward,梯度、优化器状态等)、训练数据、KV Cache……
- GPU 带宽限制:卡间的通讯时间
模型存储
分为两类:model states 和 residual states
- model states:参数、梯度、优化器状态等,必须存储
- residual states:激活值、临时存储、碎片空间等,不是必须存储,但是会在训练中产生
并行方法
流水线并行
NOTE重点
- 画流程图,分析 Bubble 占用时间
- 和 batch norm 的联系
首先是模型并行,就是将模型(尽可能均匀地)拆成几份放到不同的 GPU 上,然后依次执行 forward 和 backward,如下:

实际有效时间占比:
- :GPU 数量
- :前向/后向传播时间
利用率很低。并且空间复杂度为:
- :训练数据大小
- :模型层数
- :模型宽度
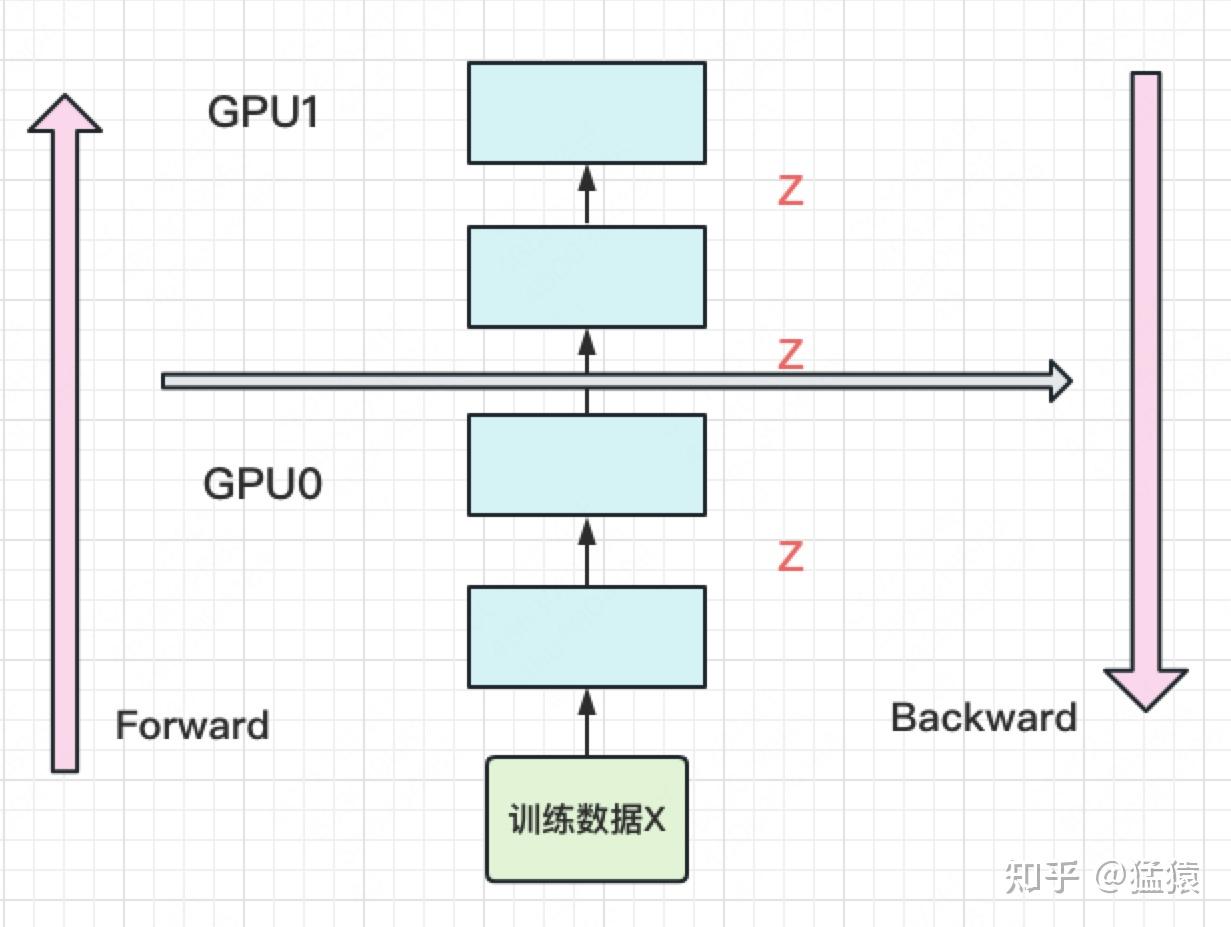
为了解决 GPU 利用率低的问题,引入流水线并行:主要使用 micro batch 技术,将一个 batch(现称为 mini batch)拆分为 个 micro batch,如下

同上推导
Gpipe 中证明当 时利用率就很高了。
但是 Batch Normalization 会有影响,Gpipe 中的处理方法是:训练时使用 micro batch 中的均值和方差,测试时使用统计的 mini batch 的平均和方差。Layer norm 则不受影响。
再解决 GPU 内存问题,使用 re-materalization 技术,即用时间换空间,几乎不存中间结果,当 backward 时再重新算一遍 forward。
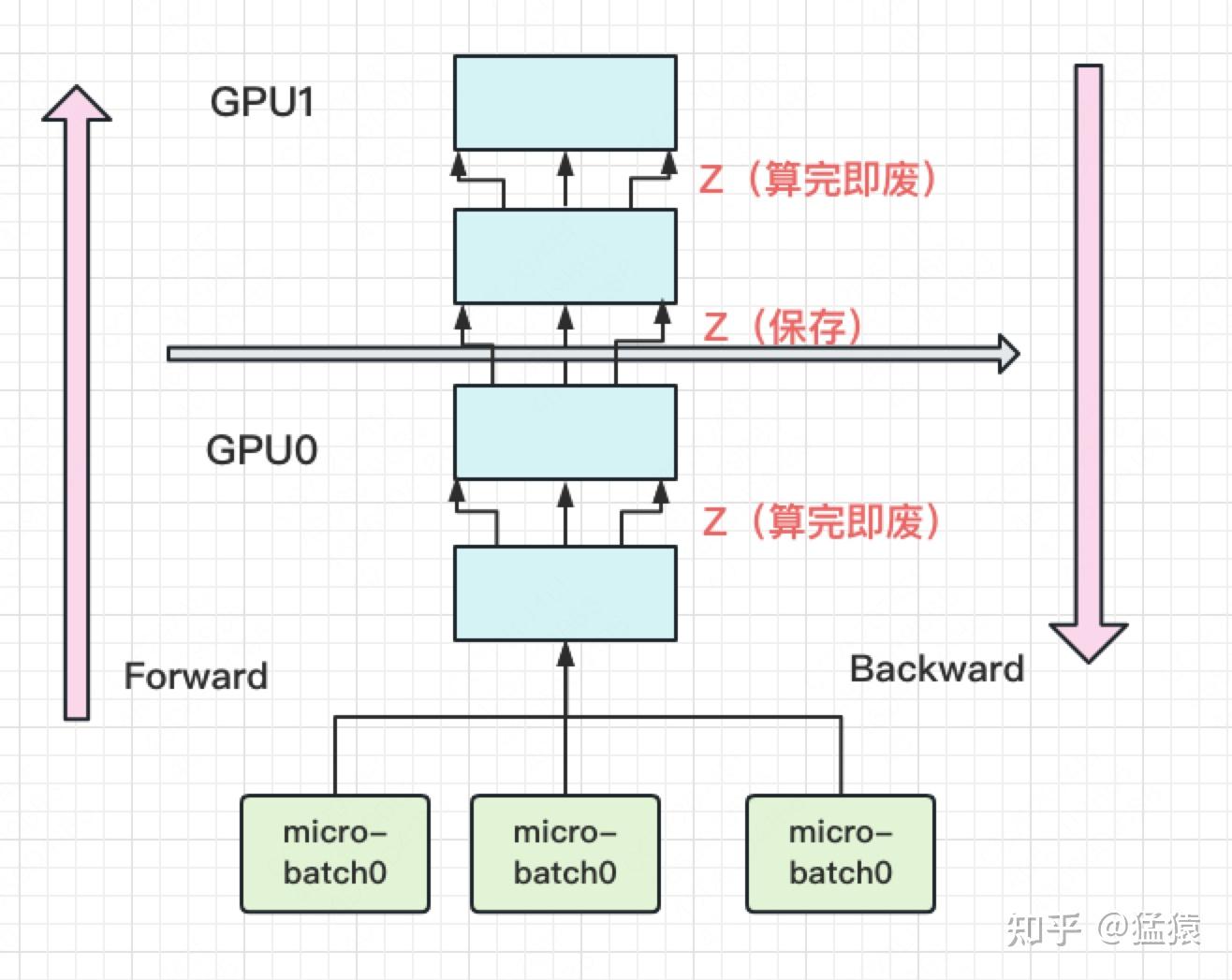
GPU 峰值时刻,空间复杂度为:
数据并行
核心是把模型拷贝几份到不同的 GPU 上,然后划分数据分别输入,计算梯度后聚合并分发到每一块 GPU 上。
DP (Data Parallelism)
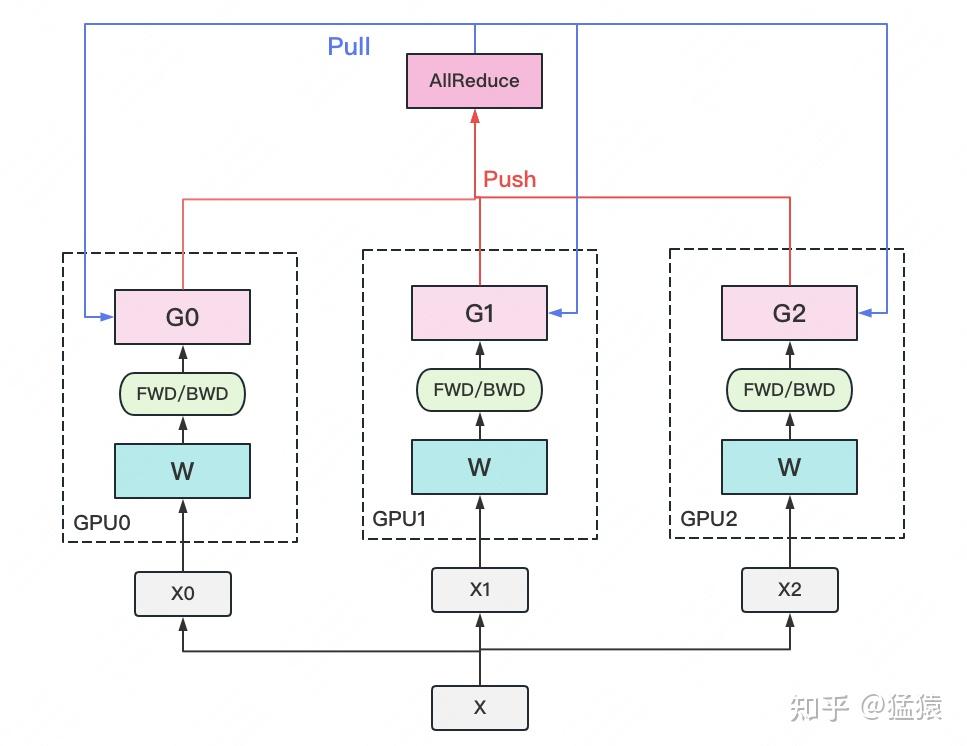
一个经典数据并行的过程如下:
- 若干块计算 GPU,如图中 GPU0~GPU2;1 块梯度收集 GPU,如图中 AllReduce 操作所在 GPU。
- 在每块计算 GPU 上都拷贝一份完整的模型参数。
- 把一份数据 X(例如一个 batch)均匀分给不同的计算 GPU。
- 每块计算 GPU 做一轮 FWD 和 BWD 后,算得一份梯度 G。
- 每块计算 GPU 将自己的梯度push给梯度收集 GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。
- 梯度收集 GPU 聚合完毕后,计算 GPU 从它那pull下完整的梯度结果,用于更新模型参数 W。更新完毕后,计算 GPU 上的模型参数依然保持一致。
- 聚合再下发梯度的操作,称为 AllReduce。
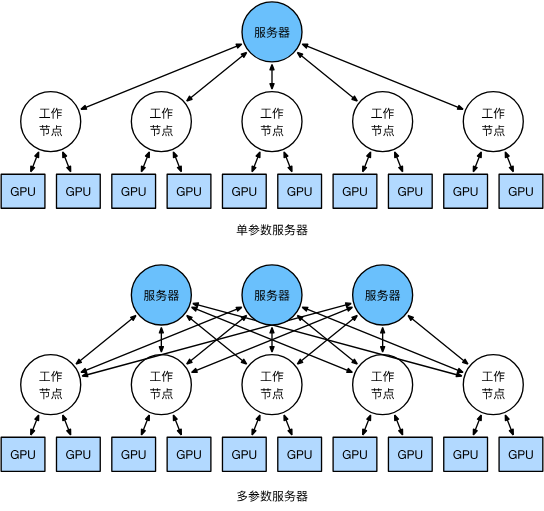
一种经典框架是参数服务器框架:计算/梯度聚合 GPU 分别称为 Worker/Server,可选择同一块 GPU 同时作为 worker 和 server.
WARNING问题:
- 每一块 GPU 上都存储模型造成存储开销大
- Server 和每一个 worker 通讯造成通讯开销大
对于通讯开销:可以使用梯度异步更新来缓解,允许一定步数的异步更新 worker 参数。但会出现模型参数过旧导致梯度聚合不容易收敛等问题,可以查阅更多资料来了解,如 Parameter-Server.pdf、12.7. 参数服务器 — 动手学深度学习 2.0.0 documentation

也可以通过多 server 的方式缓解通讯问题:
DDP (Distributed DP)
由于 server 通讯负载不均的原因,DP 一般用于单机多卡场景。可以通过将 server 上的通讯压力转移到 workers 上,来解决通讯问题。采用 Ring-AllReduce 技术。具体过程,见 图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)。而实现 Ring-AllReduce,则可以使用 NCCL。
通讯量分析:对单卡,计算发送量,Recude-Scatter 阶段 ,all-gather 阶段 ,总 , 足够大时为 。全部卡为 。这里 是 GPU 数量。说明通讯量没有变化,但是由于通讯被均匀的分配到每一个 worker 上,所以通讯时间大大减少。
ZeRO (零冗余优化)
主要思想就是切分,将任何可以被切分的东西都切开分别存储,需要的时候再从其他 GPU 上拉取过来。
数据并行的流程如下:
- 每块 GPU 上只保存部分参数 。将一个 batch 的数据分成 份,每块 GPU 各吃一份。
- 做 forward 时,对 W 做一次All-Gather,取回分布在别的 GPU 上的 ,得到一份完整的 ,单卡通讯量 。forward 做完,立刻把不是自己维护的 抛弃。
- 做 backward 时,对 做一次All-Gather,取回完整的 ,单卡通讯量 。backward 做完,立刻把不是自己维护的 抛弃。
- 做完 backward,算得一份完整的梯度 ,对 做一次Reduce-Scatter,从别的 GPU 上聚合自己维护的那部分梯度,单卡通讯量 。聚合操作结束后,立刻把不是自己维护的 G 抛弃。
- 用自己维护的 和 ,更新 。由于只维护部分 ,因此无需再对 做任何 AllReduce 操作。
- :优化器状态
- :梯度
- :权重
更具体的推导参考 图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
注意,ZeRO 形式上是模型并行,但是本质上是数据并行。
在此基础上,也发展出了
- ZeRO-Offload:将计算高的部分放入 GPU,如参数(低精度)、激活值等;同时将计算低的部分放入 CPU,如参数(高精度)、优化器状态、梯度
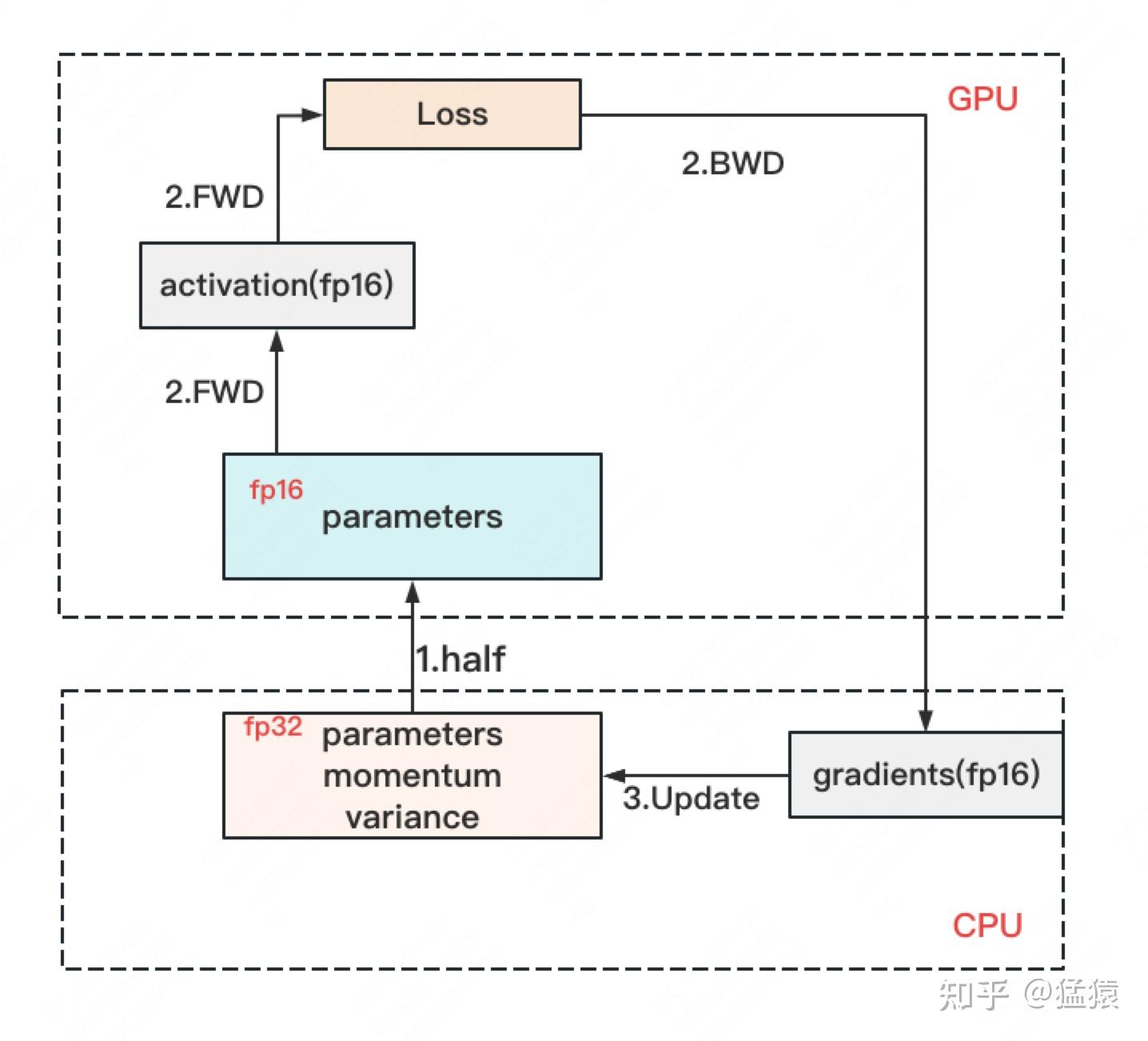
- ZeRO-infinity:同理,找一个 GPU 之外的地方存数据.
张量并行
针对 transformer 提出的方式,对权重 进行横向/纵向切分,放到不同的 GPU 上,对 MLP、attention、embedding、cross-entropy 层进行处理。
设输入为 ,形状 ,权重 ,形状 ,,形状
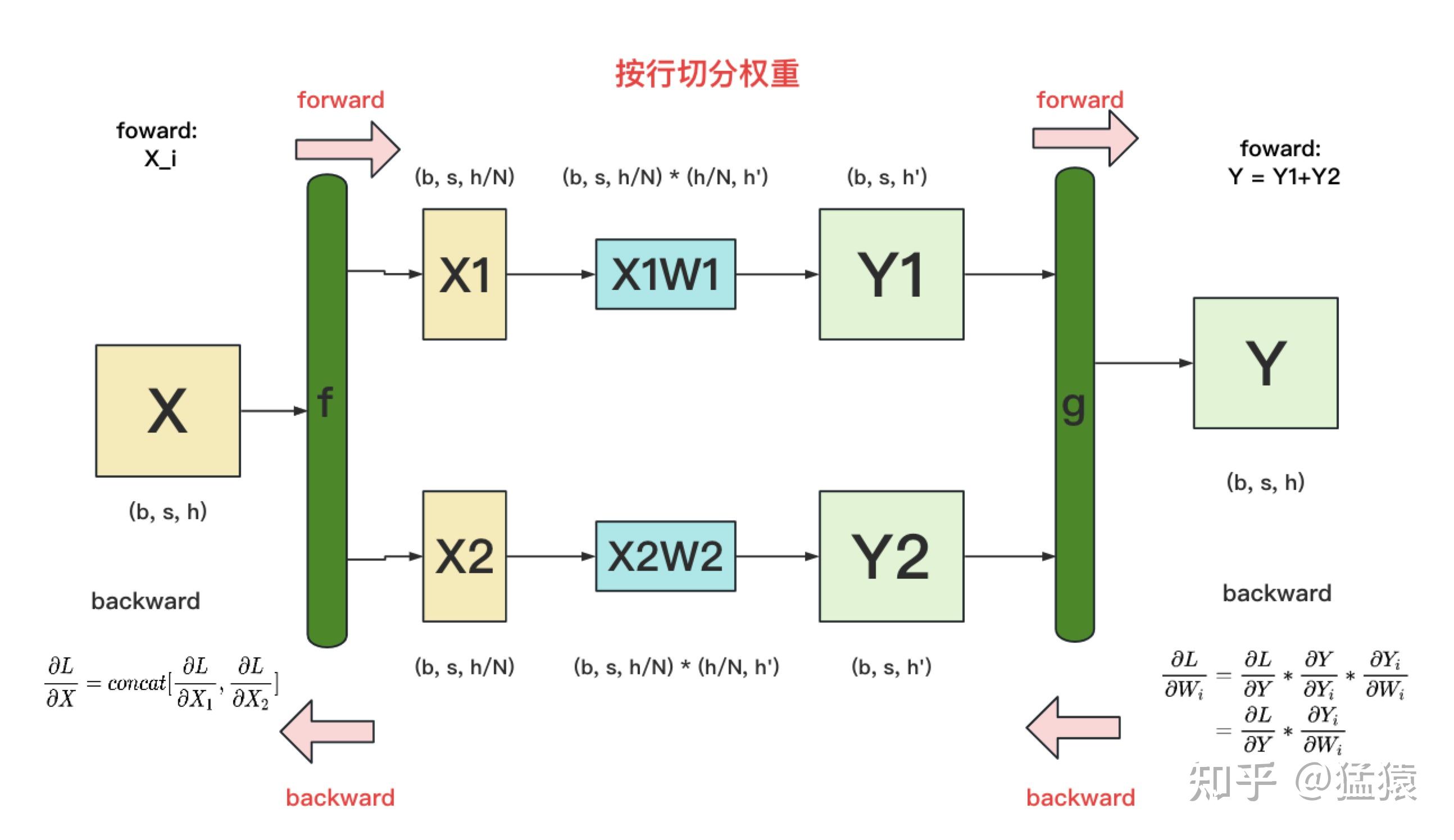
- 按行切分:
- forward:将 纵向分为 ,形状 ,权重横向分为 ,形状 ,则
- backward:将 同时广播到各个 GPU 上,分别计算出 之后进行 concatenating 即可
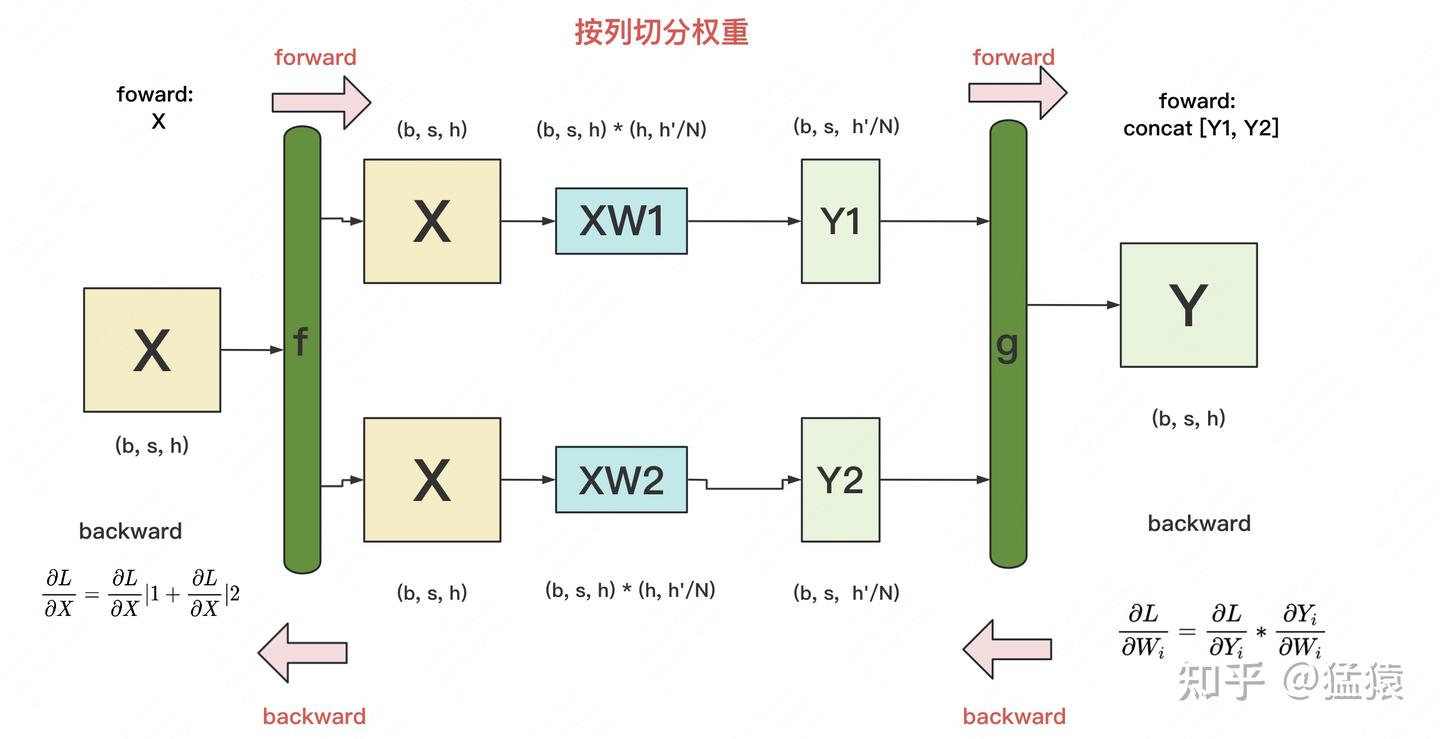
- 按列切分:
- forward:将 纵向切分为 ,形状 ,则
- backward:
举例:
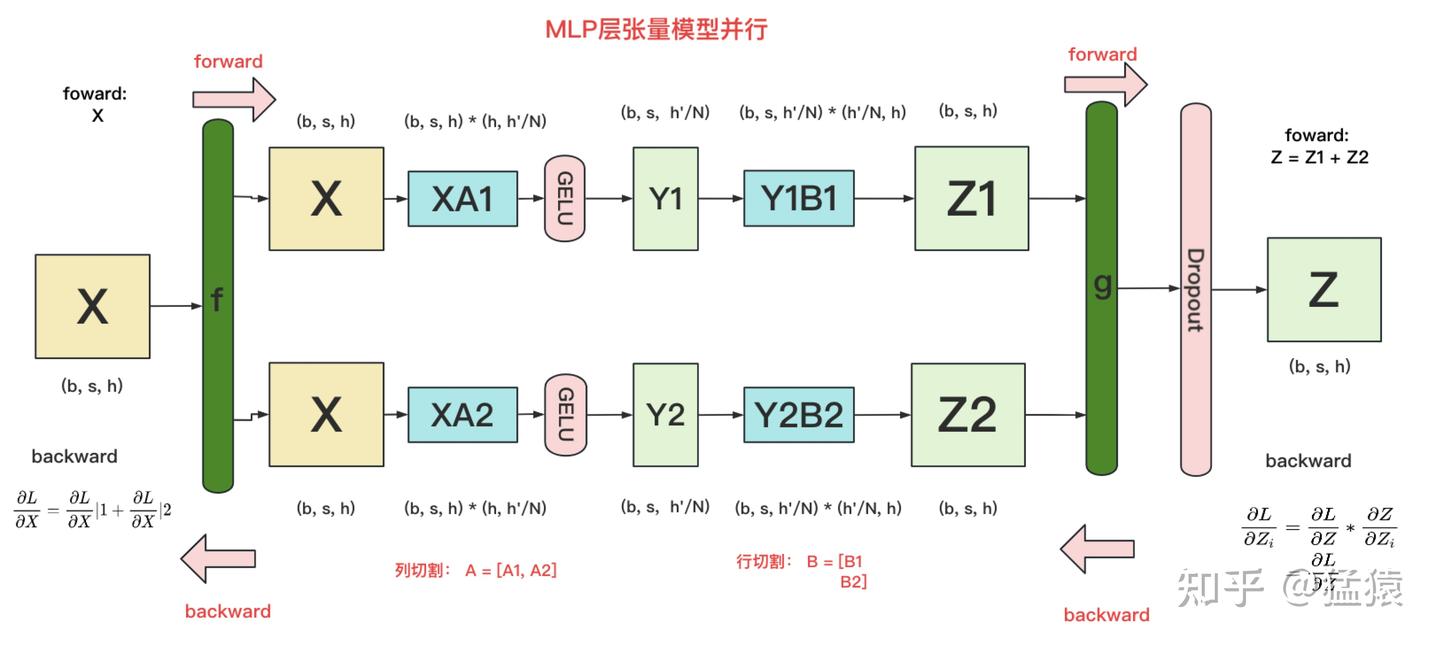
- 对 MLP,如 ,可将 按列拆分,将 按行拆分。forward 中在 处进行一次 All-Reduce,backward 过程中在 处进行一次 All-Reduce,每次通讯量 .
- 对 self-attention,有类似的处理方法,将 attention 层按列拆分,linear 层按行拆分,,仍然是 forward 和 backward 各一次通讯,总通讯量
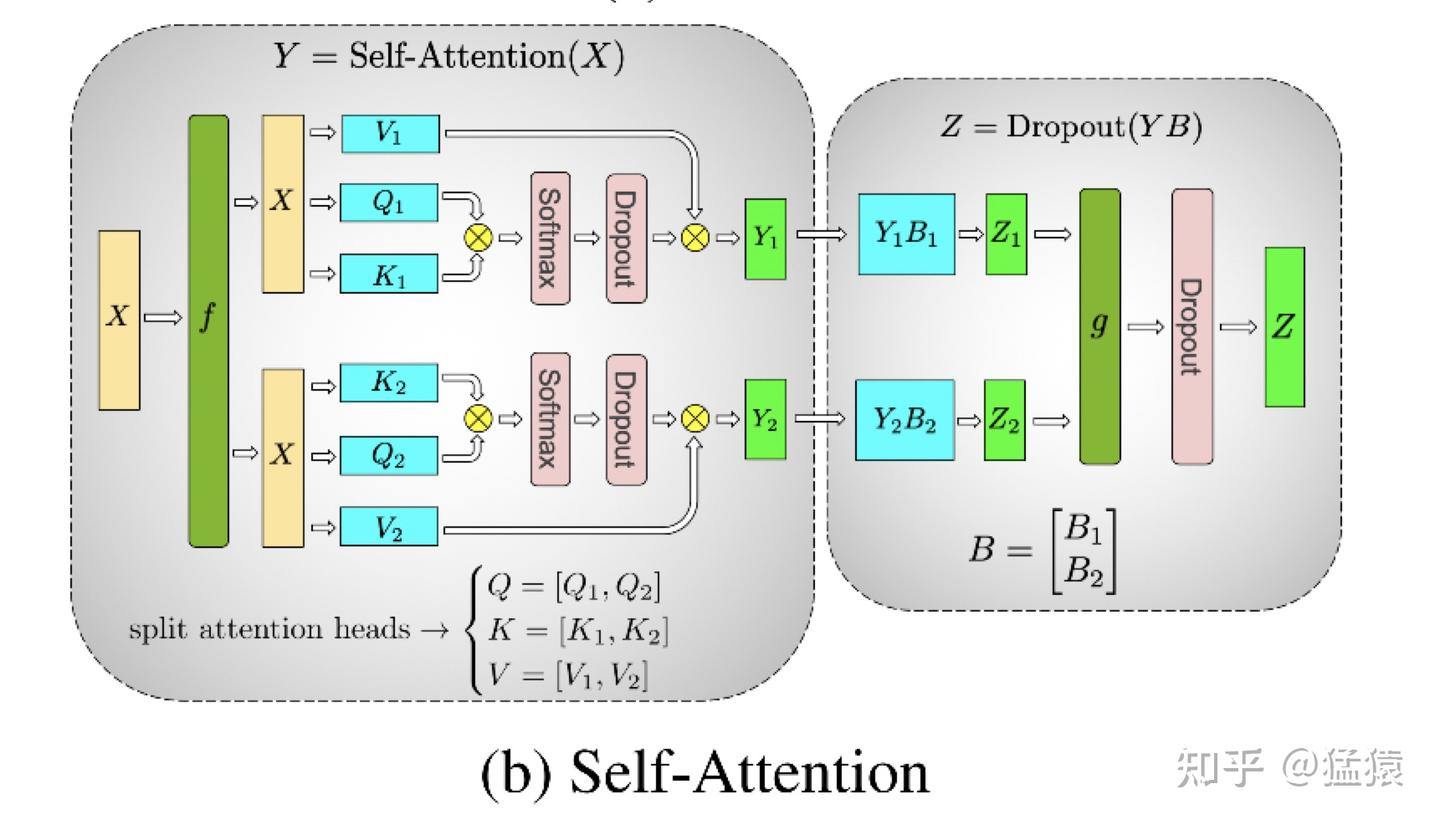
- 对于 embedding encoding,由 word embedding 和 positional embedding 构成,形状 和 。positional embedding 对短文本的模型可忽略不计。word embedding 被拆分为 份存在各个 GPU 上,若无法查询则赋值 ,然后进行一次 All-Reduce 即可
- 对于 embedding decoding,和输入层共用一个 embedding 即可。注意如果 embedding 的 encoding 和 decoding 阶段在不同的 GPU 上,则应该在参数更新前进行一次 All-Reduce。
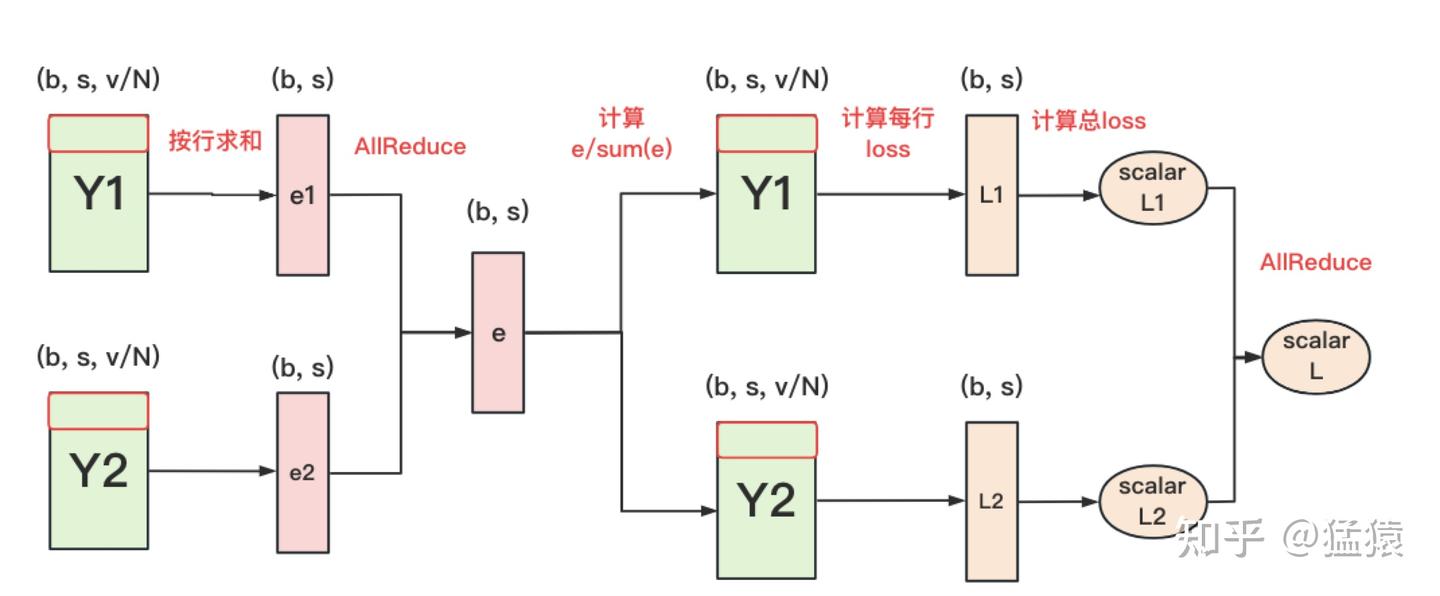
- 对于 cross entropy,由于如果在 embedding decoding 之后对结果 进行一次 All-Gather 得到最终结果 ,那么通讯量为 ,当词表过大时,开销会很大,可以进行以下优化,使通讯量降为
参考资料
- 图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例
- 图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)
- 12.7. 参数服务器 — 动手学深度学习 2.0.0 documentation
- 图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
- 图解大模型训练之:张量模型并行(TP),Megatron-LM
之后推荐看看猛猿写的同一系列的 Megetron 源码解读,加深理解。